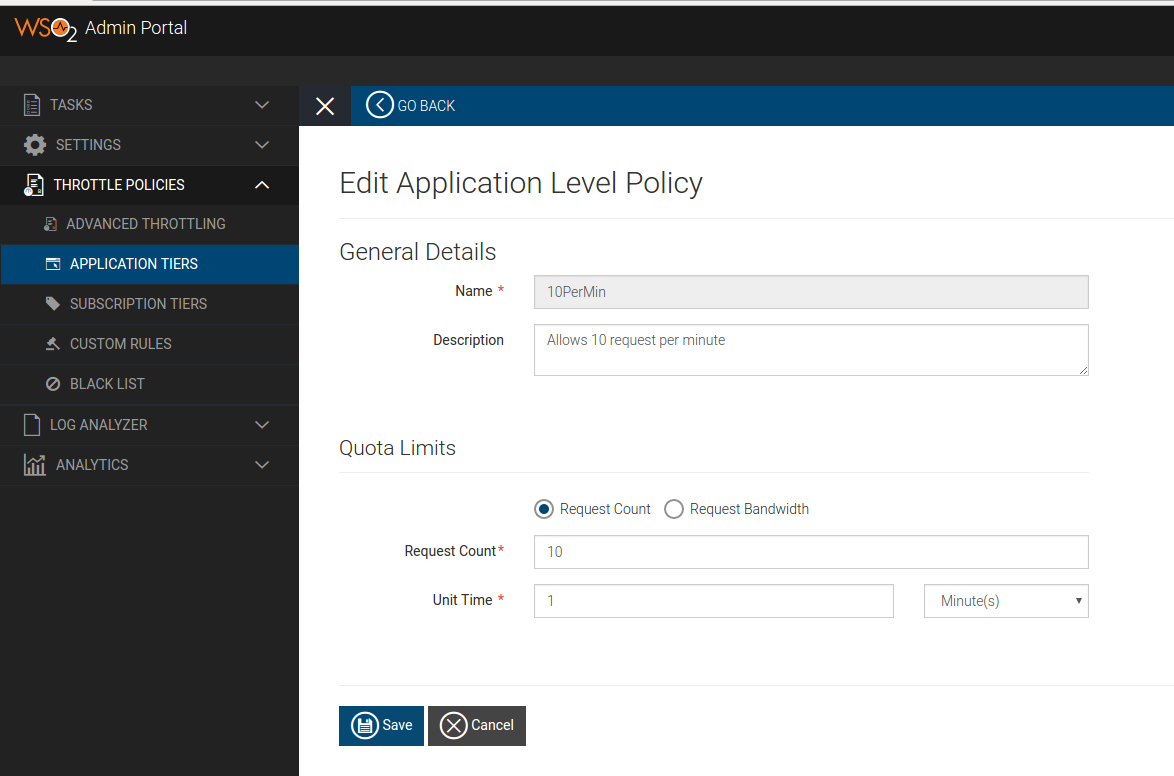
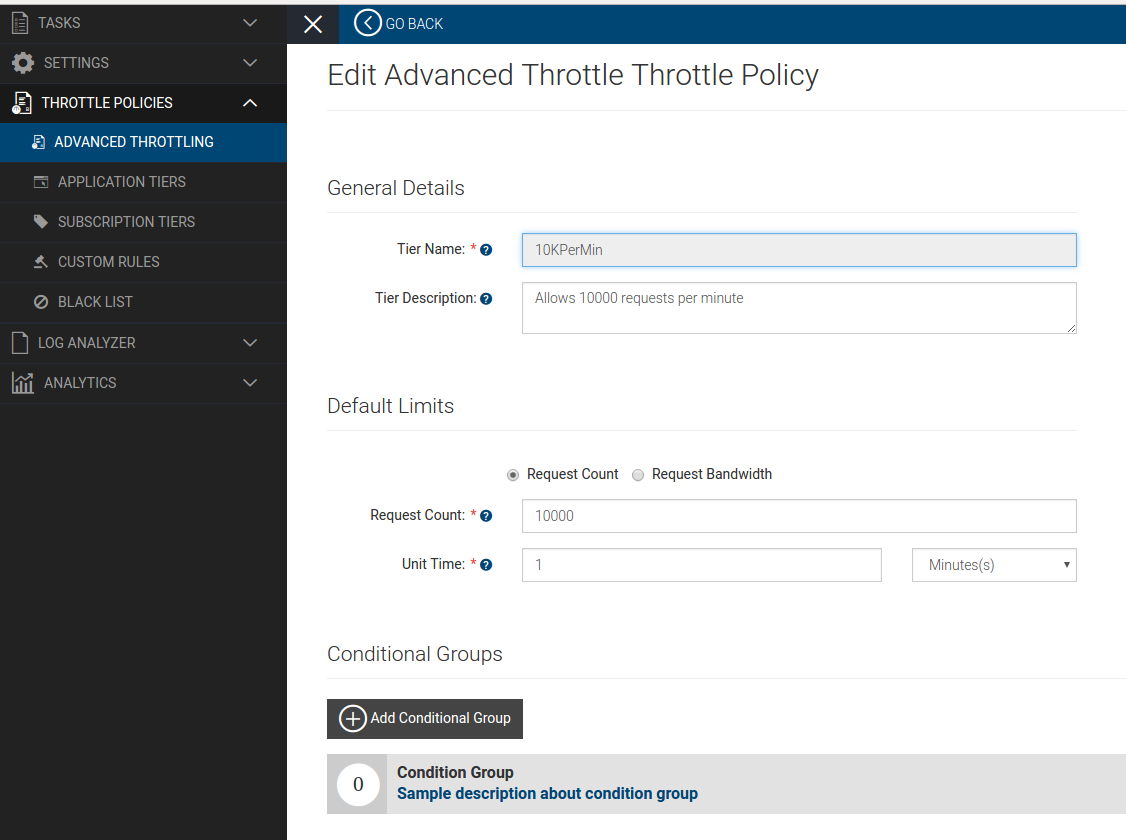
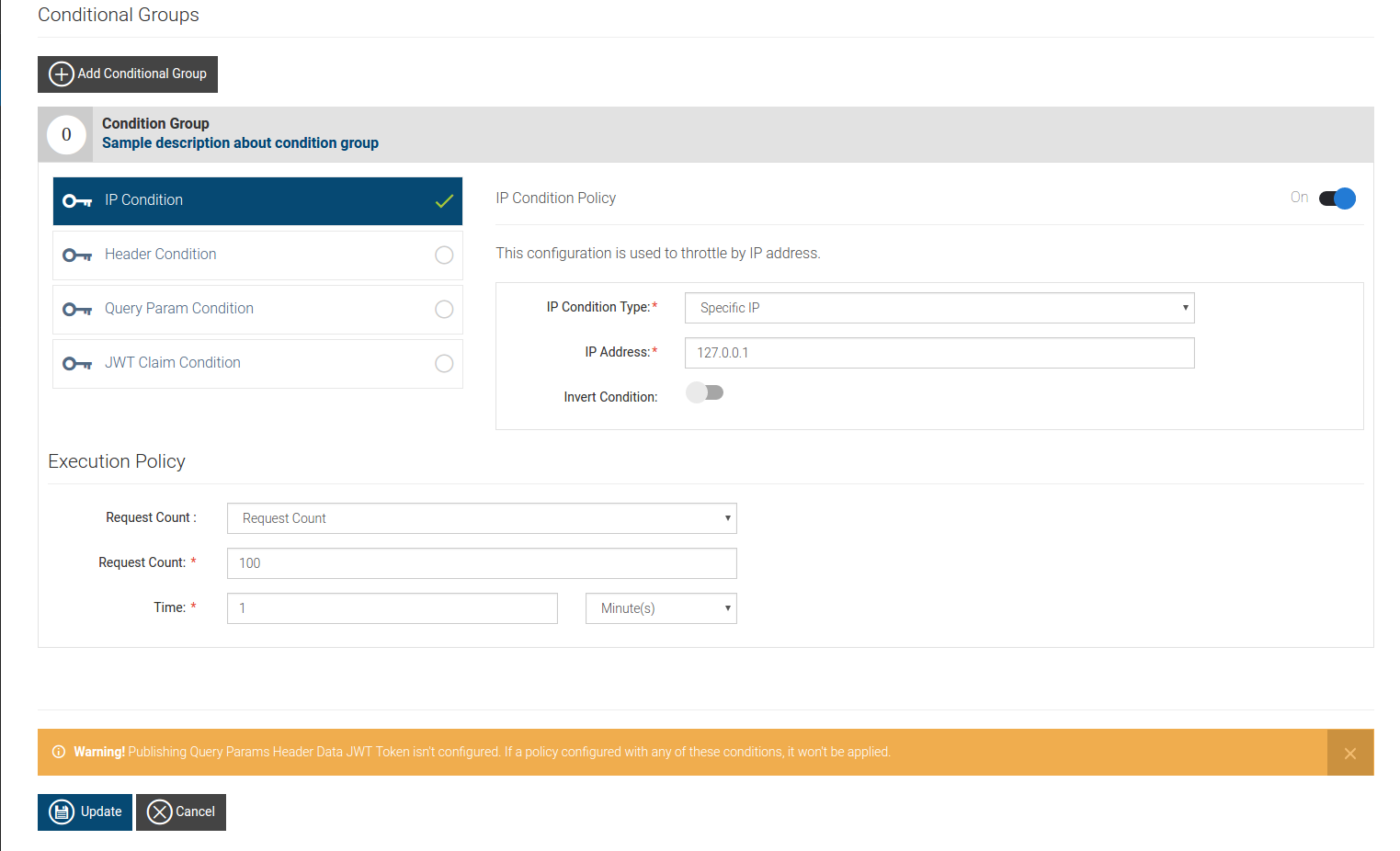
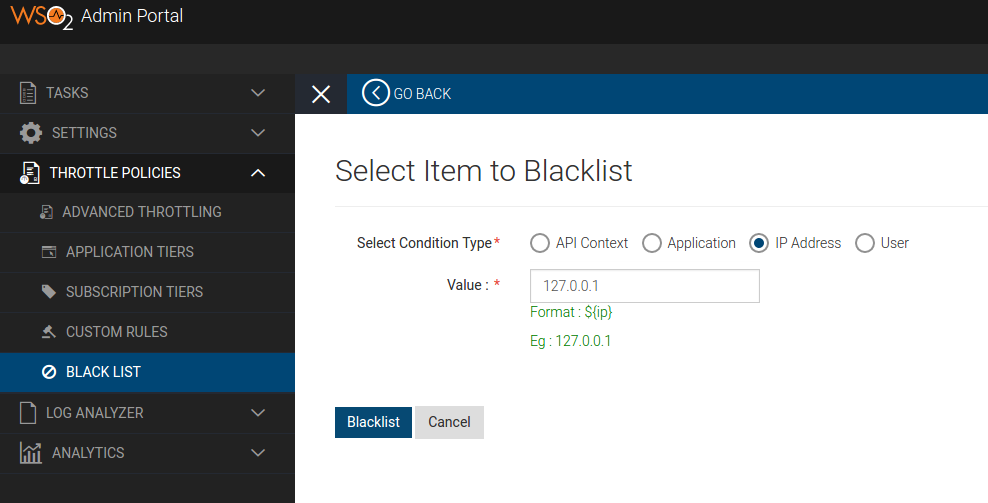
We can generate multiple access tokens and persist them to token table
using following script. With that we will generate random users and
tokens. Then insert them in to access token table. At the same time we
can write them to text file so JMeter can use that file to load tokens.
When we have multiple tokens and users then it will cause to increase
number of throttle context created in system. And it can use to generate traffic pattern which is almost same to real
production traffic.
#!/bin/bash
# Use for loop
for (( c=1; c<=100000; c++ ))
do
ACCESS_KEY=$(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 32 | head -n 1)
AUTHZ_USER=$(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 6 | head -n 1)
echo INSERT INTO "apimgt.IDN_OAUTH2_ACCESS_
echo $ACCESS_KEY >> keys3.txt
done
#!/bin/bash
# Use for loop
for (( c=1; c<=100000; c++ ))
do
ACCESS_KEY=$(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 32 | head -n 1)
AUTHZ_USER=$(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 6 | head -n 1)
echo INSERT INTO "apimgt.IDN_OAUTH2_ACCESS_
echo $ACCESS_KEY >> keys3.txt
done